kubernetes应用-deschedule-节点Pod重平衡
Pod 一旦被绑定了节点是不会触发重新调度的,由于这个特性,Kubernetes 集群在一段时间内就可能会出现不均衡的状态,所以需要均衡器来重新平衡集群.
Deschedule 简介
descheduler 组件可以对集群的 Pod 进行调度优化,descheduler 可以根据一些规则和配置策略来帮助我们重新平衡集群状态,其核心原理是根据其策略配置找到可以被移除的 Pod 并驱逐它们,其本身对 Pod 并没有调度能力,而是依靠默认的调度器来实现。
deschedule 目前支持的策略有:
-
RemoveDuplicates
-
LowNodeUtilization
-
HighNodeUtilization
-
RemovePodsViolatingInterPodAntiAffinity
-
RemovePodsViolatingNodeAffinity
-
RemovePodsViolatingNodeTaints
-
RemovePodsViolatingTopologySpreadConstraint
-
RemovePodsHavingTooManyRestarts
-
PodLifeTime
-
RemoveFailedPods
默认这些策略都是启用的,策略相关的一些参数也是可以配置的。
另外还有一些通用配置。
| Name | Default Value | Description |
|---|---|---|
| nodeSelector | nil | limiting the nodes which are processed |
| evictLocalStoragePods | false | allows |
| evictSystemCriticalPods | false | [Warning: Will evict Kubernetes system pods] allows eviction of pods with any priority, including system pods like kube-dns |
| ignorePvcPods | false | set whether PVC pods should be evicted or ignored |
| maxNoOfPodsToEvictPerNode | nil | maximum number of pods evicted from each node (summed through all strategies) |
| maxNoOfPodsToEvictPerNamespace | nil | maximum number of pods evicted from each namespace (summed through all strategies) |
| evictFailedBarePods | false | allow eviction of pods without owner references and in failed phase |
我们可以通过以下方法对这些通用配置进行配置:
|
|
安装
descheduler 可以以 Job, CronJob, 或 Deployment 资源的方式运行在集群内,选择任意一种方式安装即可。
具体安装方式可以参考官方 github
|
|
Job
|
|
CronJob
|
|
Deployment
|
|
也可以使用 Helm 和 Kustomize 进行安装,具体自行参考官方 github 进行尝试。
-
descheduler 的镜像可能因为某些原因会 down 不下来,需要梯子。
-
通常我们都是以 Cronjob 的形式跑在集群内的。
策略
我们将列举几个我们常用的策略来举例说明一下 descheduler 具体怎么使用。
PDB
在开始之前,我们最好先配置 PDB 。
由于使用 descheduler 会将 Pod 驱逐进行重调度,但是如果一个服务的所有副本都被驱逐的话,则可能导致该服务不可用。
如果服务本身存在单点故障,驱逐的时候肯定就会造成服务不可用了,这种情况我们强烈建议使用反亲和性和多副本来避免单点故障。
但是如果服务本身就被打散在多个节点上,这些 Pod 都被驱逐的话,这个时候也会造成服务不可用了,这种情况下我们可以通过配置 PDB(PodDisruptionBudget) 对象来避免所有副本同时被删除,比如我们可以设置在驱逐的时候某应用最多只有一个副本不可用,则创建如下所示的资源清单即可:
|
|
关于 PDB 的更多详细信息可以查看官方文档
所以如果我们使用 descheduler 来重新平衡集群状态,那么强烈建议给应用创建一个对应的 PodDisruptionBudget 对象进行保护。
RemoveDuplicates
该策略确保拥有 Pod 个数超过1个以上的资源对象的多个 Pod 不要运行在同一个宿主机节点上,以便更好地在集群中分散 Pod 。
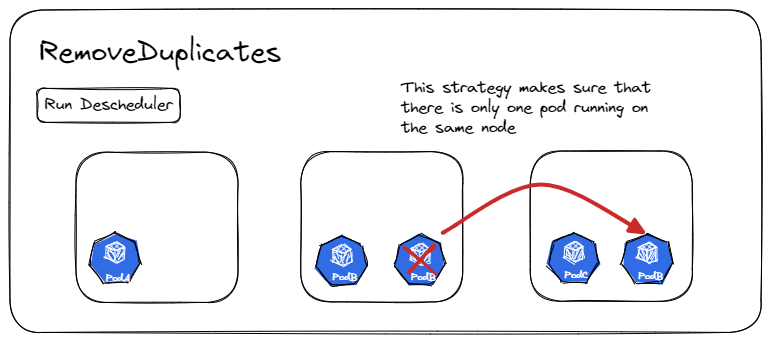
不然有如果某个节点由于某些原因崩溃了,而刚好这个资源对象的所有 Pods 都运行在这个节点上,就被一锅端了。
配置策略的时候,可以指定参数 excludeOwnerKinds 用于排除资源类型,这些类型下的 Pod 不会被驱逐。
配置:
|
|
LowNodeUtilization
该策略主要用于查找未充分利用资源的节点,并从其他节点驱逐 Pod 将它们重新调度到这些未充分利用的节点上。

-
该策略的参数可以通过字段 nodeResourceUtilizationThresholds 进行配置。
-
支持 3 支持三种基本的资源类型: cpu, memory 和 pods ,如果不指定值,则默认值都是 100% 。
-
thresholds 值不能为 nil,取值范围 [0,100]% 。
-
如果节点资源高于 targetThresholds 的阈值,则认为该节点资源利用率高,属于可能会驱逐 Pods 的潜在节点。
-
如果节点的使用率均低于所有阈值,则认为该节点未充分利用。
|
|
HighNodeUtilization
HighNodeUtilization 用来发现低利用率节点的节点,并从节点中移除 Pods ,希望这些 Pods 被紧凑地安排到更少的节点中。此策略与节点自动伸缩(CA)结合使用,旨在帮助触发低利用率节点的缩容。
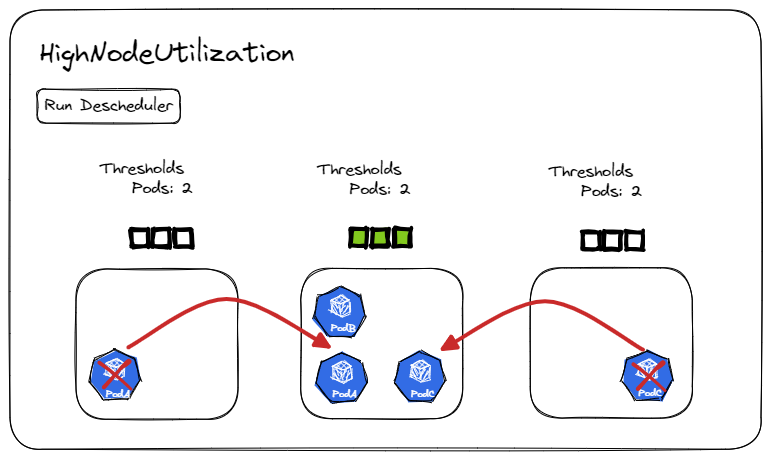
-
此策略必须与 kube-scheduler 评分策略 MostAllocated 一起使用。
-
支持 3 支持三种基本的资源类型: cpu, memory 和 Pods ,如果不指定值,则默认值都是 100% 。
-
支持拓展资源类型。如资源类型 nvidia.com/gpu 被指定 GPU 节点利用,如果没有配置阈值,将不被计算。
-
thresholds 值不能为 nil,取值范围 [0,100]% 。
配置:
|
|
RemovePodsViolatingInterPodAntiAffinity
这个策略确保从节点中删除违反 Pod 反亲和力的 Pods。
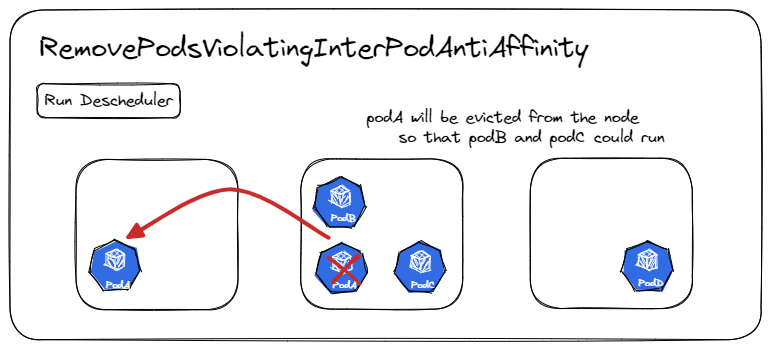
例如,在同一个节点上运行了 PodA 、 PodB 和 PodC ,其中 PodA 与 PodB 和 PodC 有反亲和规则,禁止 PodA 跟它们俩在同一个节点上运行,那么 PodA 将被从节点上驱逐出去,这样 PodB 和 PodC 就可以正常运行。当 PodB 和 PodC 在反亲和规则创建前就已经在节点上运行时,可能就会发生这种情况。
配置:
|
|
RemovePodsViolatingNodeAffinity
此策略确保从节点中删除违反节点亲和性的所有 Pods。
节点亲和规则允许 Pod 指定 requdDuringSchedulingIgnoredDuringExecution 类型,告诉调度程序在调度 Pod 时满足节点亲和,但节点随时间变化而有可能不再满足亲和性。启用该策略后,该策略将作为 RequedDuringSchedulingRequredDuringExecution 的临时实现,并将不再尊重节点亲和性的 Pod 驱逐出节点。
例如,在 nodeA 上调度了 PodA ,它满足了调度时所需的节点亲和规则 DuringSchedulingIgnoredDuringExecution。随着时间的推移 nodeA 不再满足亲和性规则。当策略执行的时候,会去检测集群中是否有另一个可用的节点满足节点亲和性规则,满足时,PodA 将从 nodeA 中被逐出。
配置:
|
|
RemovePodsViolatingNodeTaints
此策略确保删除违反节点上 NoSchedule 污点的 Pods。
例如,有一个 Pod PodA ,它能够容忍污点 key=value:NoSchedule ,PodA 被调度到打了污点的节点上运行了一段时间后,如果节点的污点被更新/删除,污点将不再满足其 PodA 的容忍度,PodA 将被驱逐。
配置:
|
|
RemovePodsViolatingTopologySpreadConstraint
该策略确保从节点驱逐违反拓扑分布约束的 Pods,具体来说,它试图驱逐将拓扑域平衡到每个约束的 maxSkew 内所需的最小 Pod 数,不过该策略需要 k8s 版本高于1.18才能使用。
默认情况下,此策略仅处理硬约束,如果将参数 includeSoftConstraints 设置为 True,也将支持软约束。
配置:
|
|
RemovePodsHavingTooManyRestarts
该策略用于删除重启次数过多的 pods。
它的参数有 podRestartThreshold,表示 pod 的重启次数达到多少时应该被驱逐(如果 includingInitContainers 为 true ,则对 Pod 下包括 InitContainer 在内的所有容器的重启次数求和)
配置:
|
|
PodLifeTime
该策略用于驱逐那些比 maxPodLifeTimeSeconds 时间更长的 pods
我们甚至可以根据状态参数指定只驱逐符合我们指定的选定条件的 Pods:
-
Pod 的状态比如: Running, Pending, PodInitializing, ContainerCreating
-
如果 Pod 的状态没有配置,默认会驱逐多有状态下的 Pod
配置:
|
|
RemoveFailedPods
该策略驱逐处于失败状态阶段的 Pods 。
-
可以提供一个可选参数来对失败的原因进行筛选。
-
通过将可选参数 includeingInitContainer 设置为 true,可以扩展到包括 InitContainer 的原因。
-
通过指定一个可选参数 minPodLifetimeSecond 来驱逐超过指定秒数的 pods 。
-
通过指定可选参数 excludeOwnerKinds ,如果 pod 的 OwnerRef 属于参数列出的任意一个类型,则不会考虑将该 pod 驱逐出去。
配置:
|
|
过滤
descheduler也考虑到驱逐Pods不能一刀切,所以提供了Pods过滤的功能。
目前有 3 种过滤维度:
-
命名空间过滤
-
优先级过滤
-
标签过滤
命名空间过滤
以下这些策略是支持基于命名空间过滤的,字段有 include 和 exclude 可选,具体看例子。
-
PodLifeTime
-
RemovePodsHavingTooManyRestarts
-
RemovePodsViolatingNodeTaints
-
RemovePodsViolatingNodeAffinity
-
RemovePodsViolatingInterPodAntiAffinity
-
RemoveDuplicates
-
RemovePodsViolatingTopologySpreadConstraint
-
RemoveFailedPods
-
LowNodeUtilization and HighNodeUtilization (Only filtered right before eviction)
例子:
|
|
这样就只针对 namespace1 和 namespace2 下的 Pods 生效。exclude 字段的配置也跟上面的类似:
|
|
exclude 和 include 包含的命名空间不能重叠。
优先级过滤
所有策略都可以配置优先级阈值,只有在该阈值以下的 Pods 才能被驱逐。
您可以通过设置 thresholdPriorityClassName (将阈值设置为给定优先级类别的值)或 thresholdPriority (直接设置阈值)参数来指定此阈值。默认情况下,此阈值设置为系统集群关键优先级类别的值。
evictSystemCriticalPods 为 true 则优先级过滤的功能会失效。基于 thresholdPriority 配置:
|
|
基于 thresholdPriorityClassName 设置:
|
|
标签过滤
以下的策略可以基于 kubernetes 的 labelSelector 规则,来根据 Pods 标签来过滤:
-
PodLifeTime
-
RemovePodsHavingTooManyRestarts
-
RemovePodsViolatingNodeTaints
-
RemovePodsViolatingNodeAffinity
-
RemovePodsViolatingInterPodAntiAffinity
-
RemovePodsViolatingTopologySpreadConstraint
-
RemoveFailedPods
配置:
|
|
节点适配
以下策略可以使用
nodeFit参数来优化调度:
-
RemoveDuplicates
-
LowNodeUtilization
-
HighNodeUtilization
-
RemovePodsViolatingInterPodAntiAffinity
-
RemovePodsViolatingNodeAffinity
-
RemovePodsViolatingNodeTaints
-
RemovePodsViolatingTopologySpreadConstraint
-
RemovePodsHavingTooManyRestarts
-
RemoveFailedPods
如果设置为 true ,不管 Pod 是否满足驱逐标准,在驱逐之前会先适配是否有可供调度的节点,如果没有可供调度的节点,则 Pod 不会被驱逐。
当 nodeFit 为 true ,会评估 Pod 以下情况:
-
是否配置了
nodeSelector -
Pod是否配置了容忍度,是否有满足容忍度的节点 -
Pod是否配置了nodeAffinity -
节点资源是否足够满足
Pod调度 -
节点是否不可达
配置:
|
|
结束
使用
descheduler的一些总结和需要注意的点。
-
基于
Request计算节点负载并不能反映真实情况。在源码
descheduler/pkg/descheduler/node/node.go中可以看到,descheduler是通过合计Node上Pod的Request值来计算使用情况的。如果能直接拿
metrics-server或者Prometheus中的数据,会更准确一点。 -
驱逐
Pod导致应用不稳定。descheduler通过策略计算出一系列符合要求的Pod,进行驱逐。它不会驱逐没有副本控制器的
Pod,不会驱逐带本地存储的Pod等,保障在驱逐时,不会导致应用故障。在源码descheduler\pkg\descheduler\evictions\evictions.go中可以看到它使用err := client.PolicyV1().Evictions(eviction.Namespace).Evict(ctx, eviction)来驱逐Pod时,该方法在驱逐Pod时,会先删掉Pod再重新启动,而不是滚动更新。在高并发的场景下,这种暴力驱逐会导致服务出现大量
4xx/5xx的错误,如果对SLA有比较高的要求的话,请谨慎使用。 -
依赖于
Kubernetes的调度策略。descheduler并没有实现调度器,而是依赖于Kubernetes的调度器。这也意味着,
descheduler能做的事情只是驱逐Pod,让Pod重新走一遍调度流程。如果节点数量很少,descheduler可能会频繁的驱逐Pod,而且Pod还不一定会按照我们配置的策略实现想要的效果。 -
关键性
Pods不会为驱逐。比如
priorityClassName设置为system-cluster-critical或system-node-critical的Pods。