利用 Informer 机制来开发一个简单的 controller 来清理 kubernetes 集群内异常状态的 pod .
背景
平时 kubernetes 集群经常出现各种 pod 状态异常的情况,虽然有告警提示,但是每次等告警发出的时候已经慢了一拍了,甚至有时候告警被刷屏都没能看到告警的内容而错误最佳处理时机,如果我们自己开发一个 controller 专门来处理这类问题,那可以节省不少精力。
实现
我们暂时将我们要开发的服务称之为 ops-pod-cleaner ,具体功能如下:
在开始前,首先我们先对 client-go 有个大概的了解
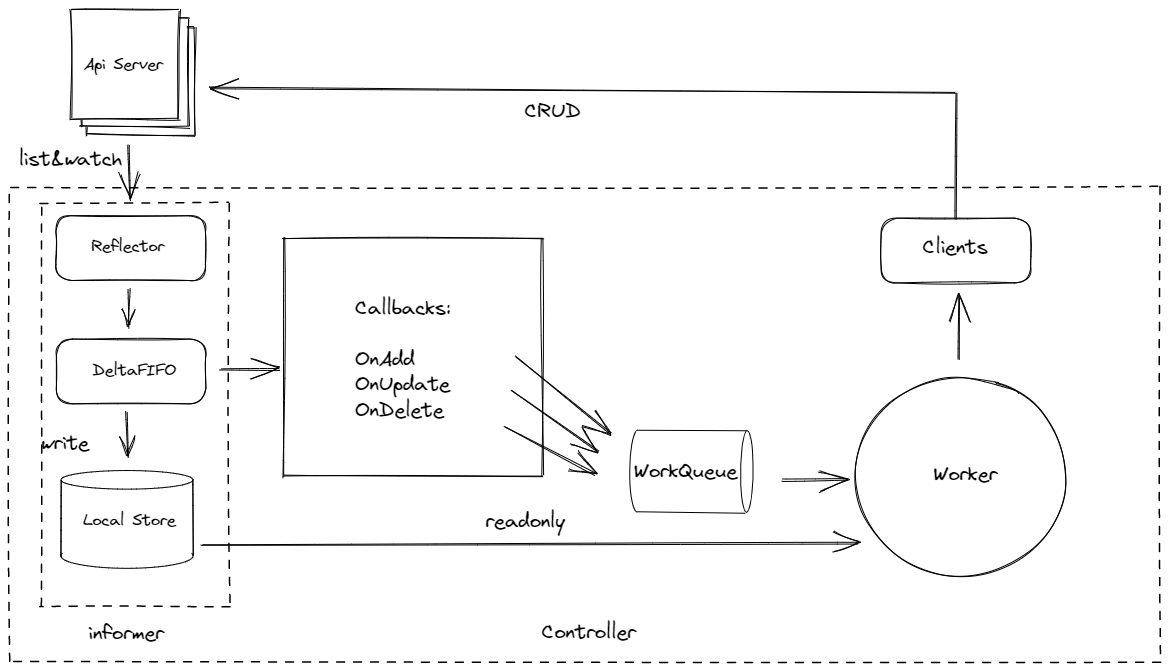
client-go 架构如图:
Client-go 架构图
从上面的架构图中,我们的服务逻辑主要定义在 Worker 中,具体逻辑如下
Client-go 架构图
服务从 Reflector 获取 api server 的 events ,监听到事件后,将事件存入到 DeltaFIFO 队列,并存储到本地缓存。
Worker 从工作队列 获取要被处理的 pod 的信息。
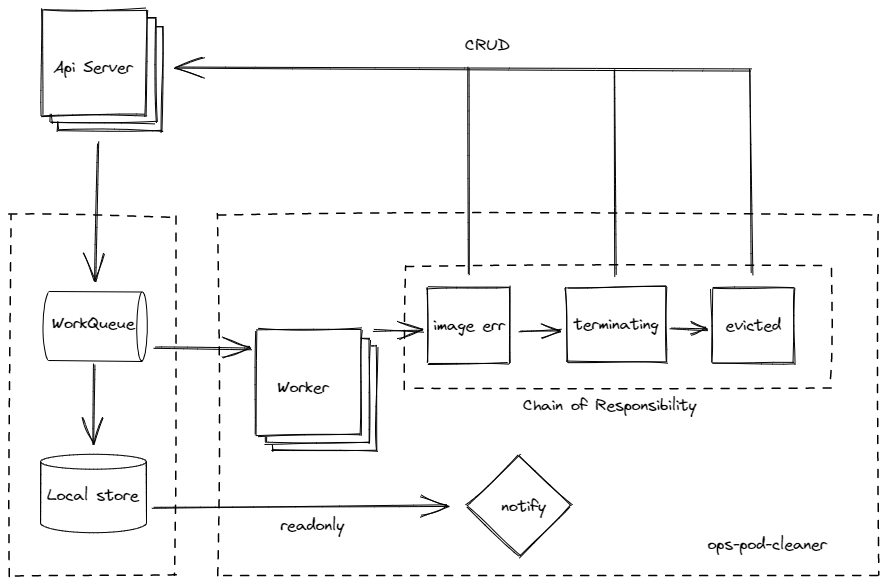
Worker 将 pod 实例信息传递到 Worker 内部逻辑代码处理,此处逻辑代码部分使用责任链设计模式 ,层层向下传递,第一层判断 pod 是不是被驱逐的,不是的话传递给第二层,判断是不是一直卡住 terminating 状态的,直至任务结束。
定期获取指定命名空间下重启次数过多且状态异常的服务,生成报告并将结果发送到飞书告警群。
编码
我们这边主要分享具体的一些思路和实现,源码部分暂时不对外公开。
初始化
因为我们的环境大量使用 Argo Rollout 去做服务部署,所以初始部分会涉及到 2 个客户端类型的初始化:Clientset、DynamicClient
因为初始化过程只需要一次,因此我们在设计上,使用单例模式,clientSet,dynamicClient 2 个客户端属于私有变量,通过 GetClientSet、GetDynamicClient 暴漏给其他包调用,避免 clientSet,dynamicClient 属性在程序使用过程中被修改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
func InitClient () ( * kubernetes . Clientset , error ) {
var err error
var config * rest . Config
// inCluster(Pod)、KubeConfig(kubectl)
var kubeconfig * string
if home := homedir . HomeDir (); home != "" {
kubeconfig = flag . String ( "kubeconfig" , filepath . Join ( home , ".kube" , "config" ), "(可选) kubeconfig 文件的绝对路径" )
} else {
kubeconfig = flag . String ( "kubeconfig" , "" , "kubeconfig 文件的绝对路径" )
}
flag . Parse ()
// 首先使用 inCluster 模式(需要去配置对应的 RBAC 权限,默认的sa是default->是没有获取deployments的List权限)
if config , err = rest . InClusterConfig (); err != nil {
// 使用 KubeConfig 文件创建集群配置 Config 对象
if config , err = clientcmd . BuildConfigFromFlags ( "" , * kubeconfig ); err != nil {
panic ( err . Error ())
}
}
// 已经获得了 rest.Config 对象
// 创建 Clientset 对象
clientSet , err = kubernetes . NewForConfig ( config )
if err != nil {
panic ( err . Error ())
}
// 创建 DynamicClient 对象
dynamicClient , err = dynamic . NewForConfig ( config )
if err != nil {
panic ( err . Error ())
}
return clientSet , nil
}
// clientSet 暴露给其他包用
func GetClientSet () * kubernetes . Clientset {
return clientSet
}
// dynamicClient 暴露给其他包用
func GetDynamicClient () dynamic . Interface {
return dynamicClient
}
控制器
我们通过定义一个 Controller 结构体,来实现一个简单的 Controller 实例和具体的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 定义一个 Controller 结构体
type Controller struct {
// 收到具体的事件后丢个工作队列处理
queue workqueue . RateLimitingInterface
// 从本地缓存获取资源信息
informer cache . SharedIndexInformer
}
// 定义一个 NewController 方法,共入口层在程序启动的时候初始化用
func NewController ( queue workqueue . RateLimitingInterface , informer cache . SharedIndexInformer ) * Controller {
return & Controller {
informer : informer ,
queue : queue ,
}
}
控制器的启动函数 Run ,一切的开始
我们可以看到函数内部使用 go wait.Until(c.runWorker, time.Second, stopCh) 这个来使用跑一个 Worker 处理事件。<-stopCh 用来阻止 Run 函数退出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// Run 开始 watch 和同步
func ( c * Controller ) Run ( threadiness int , stopCh chan struct {}) {
defer runtime . HandleCrash ()
// 停止控制器后关掉队列
defer c . queue . ShutDown ()
klog . Info ( "Starting Pod controller" )
for i := 0 ; i < threadiness ; i ++ {
go wait . Until ( c . runWorker , time . Second , stopCh )
}
// 阻止Run函数退出,用其他channel也可以
<- stopCh
klog . Info ( "Stoping Pod controller" )
}
stopCh
我们经常会在控制器 Run(threadiness int, stopCh <-chan struct{}) 函数里面看到 stopCh <-chan struct{} 参数,在 Run 结束前会 <-stopCh 阻塞 Run 函数退出。我们来看看空结构体 struct{} 具体含义:
空结构体的宽度是0,占用了0字节的内存空间。
实际上 struct{} 就是一种普通数据类型,只是没有具体的值而已。
通常 struct{} 类型 channel 的用法是使用同步,一般不需要往 channel 里面写数据,只有读等待,而读等待会在 channel 被关闭的时候返回。
close(stopCh) 所有携程都会收到 channel 的关闭通知,也可以通过往 stopCh 写入数据来通知携程,在 Run 函数中,写入一个数据会首先被 Run 函数接收到,Run 函数会退出,再往里面写数据,会被 Run 里面的 goroutine 携程接收,接收到通知携程也会相应地做出接收后的响应。
channel 对象一定要 make 出来才能使用。
Worker 的逻辑代码如下
从队列取出 key ,根据 key 去本地缓存查找 pod 的具体信息。(本地缓存跟 api server 的 etcd 库里面的数据保持一致)
获取 pod 信息后实例化 podPorcessor 处理器
交给给逻辑层处理器处理完任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// 此外重试逻辑不应成为业务逻辑的一部分。
func ( c * Controller ) syncToLogicHandle ( key string ) error {
// 从本地存储中获取 key 对应的对象
// informer.GetIndexer() 获取Indexer对象
obj , exists , err := c . informer . GetIndexer (). GetByKey ( key )
if err != nil {
klog . Errorf ( "Fetching object with key %s from store failed with %v" , key , err )
return err
}
if ! exists {
// klog.Infof("Pod %s 已经不存在了 \n", key)
} else {
// 业务逻辑,调用责任链判断要执行哪个功能
podInstance := & service . PodInstance {
Pod : obj .( * v1 . Pod ),
HasProcessed : false ,
IsSetZero : cf . Conf . SetZeroConfigByErrImagePull . Enable ,
IsDelEvicted : cf . Conf . AutoDelteEvictedPod . Enable ,
IsDelterminating : cf . Conf . AutoDelteTerminatingPod . Enable ,
}
podPorcessor := service . BuildPodProcessorChain ()
go podPorcessor . ProcessFor ( podInstance )
}
return nil
}
podPorcessor 的实现原理如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
package service
import (
"fmt"
v1 "k8s.io/api/core/v1"
)
// PodProcessor pod处理过程中,各节点统一处理接口
type PodProcessor interface {
SetNextProcessor ( processor PodProcessor )
ProcessFor ( podInstance * PodInstance )
}
// pod 实例
type PodInstance struct {
Pod * v1 . Pod
HasProcessed bool
IsSetZero bool
IsDelEvicted bool
IsDelterminating bool
}
// basePodProcessor pod流程处理器基类
type basePodProcessor struct {
// nextProcessor 下一个pod处理流程
nextProcessor PodProcessor
}
// SetNextProcessor 基类中统一实现设置下一个处理器方法
func ( b * basePodProcessor ) SetNextProcessor ( processor PodProcessor ) {
b . nextProcessor = processor
}
// ProcessFor 基类中统一实现下一个处理器流转
func ( b * basePodProcessor ) ProcessFor ( podInstance * PodInstance ) {
if b . nextProcessor != nil {
b . nextProcessor . ProcessFor ( podInstance )
}
}
// evictedProcessor pod驱逐状态处理的处理器
type evictedProcessor struct {
basePodProcessor // 引用基类
}
func ( b * evictedProcessor ) ProcessFor ( podInstance * PodInstance ) {
// 如果处理状态为true则后续不用传递到下一处理器
if podInstance . HasProcessed {
return
}
// 处理逻辑,删除状态异常的pod
ok , err := autoDelEvictedPod ( podInstance . Pod )
if err != nil {
fmt . Printf ( "Pod %s 处理驱逐状态时出错 %s;\n" , podInstance . Pod . Name , err )
}
// 如果 ok 则直接退出流程
if ok {
return
}
// 如果pod在这里没有做处理,则进入下一个流程处理
b . basePodProcessor . ProcessFor ( podInstance )
}
// terminating pod一直卡在terminating状态处理的处理器
type terminatingProcessor struct {
basePodProcessor // 引用基类
}
func ( b * terminatingProcessor ) ProcessFor ( podInstance * PodInstance ) {
// 如果处理状态为true则后续不用传递到下一处理器
if podInstance . HasProcessed {
return
}
// 处理逻辑,删除状态异常的pod
ok , err := autoDelTerminatingPod ( podInstance . Pod )
if err != nil {
fmt . Printf ( "Pod %s 处理驱逐状态时出错 %s;\n" , podInstance . Pod . Name , err )
}
// 如果 ok 则直接退出流程
if ok {
return
}
// 如果pod在这里没有做处理,则进入下一个流程处理
b . basePodProcessor . ProcessFor ( podInstance )
}
// setZeroProcessor pod镜像拉取错误处理的处理器
type setZeroProcessor struct {
basePodProcessor // 引用基类
}
func ( b * setZeroProcessor ) ProcessFor ( podInstance * PodInstance ) {
// 如果处理状态为true则后续不用传递到下一处理器
if podInstance . HasProcessed {
return
}
// 处理逻辑,删除状态异常的pod
ok , err := autoSetZeroByErrImagePull ( podInstance . Pod )
if err != nil {
fmt . Printf ( "Pod %s 处理驱逐状态时出错 %s;\n" , podInstance . Pod . Name , err )
}
// 如果 ok 则直接退出流程
if ok {
return
}
// 如果pod在这里没有做处理,则进入下一个流程处理
b . basePodProcessor . ProcessFor ( podInstance )
}
// BuildPodProcessorChain 构建pod流程处理链
func BuildPodProcessorChain () PodProcessor {
setZeroProcessorNode := & setZeroProcessor {}
terminatingProcessorNode := & terminatingProcessor {}
terminatingProcessorNode . SetNextProcessor ( setZeroProcessorNode )
evictedProcessorNode := & evictedProcessor {}
evictedProcessorNode . SetNextProcessor ( terminatingProcessorNode )
return evictedProcessorNode
}
具体实现过程看注释 , 这里不做赘述 。
最后我们来看看 Controller 的完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
type Controller struct {
// indexer cache.Indexer
queue workqueue . RateLimitingInterface
informer cache . SharedIndexInformer
}
func NewController ( queue workqueue . RateLimitingInterface , informer cache . SharedIndexInformer ) * Controller {
return & Controller {
informer : informer ,
// indexer: indexer,
queue : queue ,
}
}
func ( c * Controller ) processNextItem () bool {
// 等到工作队列中有一个新元素
key , quit := c . queue . Get ()
if quit {
return false
}
// 告诉队列我们已经完成了处理此 key 的操作
// 这将为其他 worker 解锁该 key
// 这将确保安全的并行处理,因为永远不会并行处理具有相同 key 的两个Pod
defer c . queue . Done ( key )
// 调用包含业务逻辑的方法
err := c . syncToLogicHandle ( key .( string ))
// 如果在执行业务逻辑期间出现错误,则处理错误
c . handleErr ( err , key )
return true
}
// syncToLogicHandle 是控制器的业务逻辑实现,函数名随便定义
// 如果发生错误,则简单地返回错误
// 此外重试逻辑不应成为业务逻辑的一部分。
func ( c * Controller ) syncToLogicHandle ( key string ) error {
// 从本地存储中获取 key 对应的对象
// informer.GetIndexer() 获取Indexer对象
obj , exists , err := c . informer . GetIndexer (). GetByKey ( key )
if err != nil {
klog . Errorf ( "Fetching object with key %s from store failed with %v" , key , err )
return err
}
if ! exists {
// klog.Infof("Pod %s 已经不存在了 \n", key)
} else {
// 业务逻辑,调用责任链判断要执行哪个功能
podInstance := & service . PodInstance {
Pod : obj .( * v1 . Pod ),
HasProcessed : false ,
IsSetZero : cf . Conf . SetZeroConfigByErrImagePull . Enable ,
IsDelEvicted : cf . Conf . AutoDelteEvictedPod . Enable ,
IsDelterminating : cf . Conf . AutoDelteTerminatingPod . Enable ,
}
podPorcessor := service . BuildPodProcessorChain ()
go podPorcessor . ProcessFor ( podInstance )
}
return nil
}
// 检查是否发生错误,并确保我们稍后重试
func ( c * Controller ) handleErr ( err error , key interface {}) {
if err == nil {
// 忘记每次成功同步时 key 的#AddRateLimited历史记录。
// 这样可以确保不会因过时的错误历史记录而延迟此 key 更新的以后处理。
c . queue . Forget ( key )
return
}
//如果出现问题,此控制器将重试5次
if c . queue . NumRequeues ( key ) < 5 {
klog . Infof ( "Error syncing pod %v: %v" , key , err )
// 重新加入 key 到限速队列
// 根据队列上的速率限制器和重新入队历史记录,稍后将再次处理该 key
c . queue . AddRateLimited ( key )
return
}
c . queue . Forget ( key )
// 多次重试,我们也无法成功处理该key
runtime . HandleError ( err )
klog . Infof ( "Dropping pod %q out of the queue: %v" , key , err )
}
// Run 开始 watch 和同步
func ( c * Controller ) Run ( threadiness int , stopCh chan struct {}) {
defer runtime . HandleCrash ()
// 停止控制器后关掉队列
defer c . queue . ShutDown ()
klog . Info ( "Starting Pod controller" )
for i := 0 ; i < threadiness ; i ++ {
go wait . Until ( c . runWorker , time . Second , stopCh )
}
// 阻止Run函数退出,用其他channel也可以
<- stopCh
klog . Info ( "Stoping Pod controller" )
}
func ( c * Controller ) runWorker () {
for c . processNextItem () {
}
}
// report
func ( c * Controller ) Report ( stopCronCh chan struct {}) {
duration := cf . Conf . SetZeroConfigByTooManyRestart . Duration
isenable := cf . Conf . SetZeroConfigByTooManyRestart . Enable
if isenable {
job := cron . New ()
job . AddFunc ( duration , func () {
// 业务逻辑
objs := c . informer . GetIndexer (). List ()
service . AutoSendReport ( objs )
})
job . Start ()
// defer job.Stop()
}
<- stopCronCh
klog . Infoln ( "stoping cronjob" )
}
可配置
需要自定义天数、重启次数、命名空间等参数,可供我们自由选择
我们可以通过第三方库库 viper 来读取 yaml 格式的配置文件,配置文件我们可以通过 configmap 的方式挂载进容器里面。
具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
// 系统配置,对应yml
// viper内置了mapstructure, yml文件用"-"区分单词, 转为驼峰方便
// 全局配置变量
var Conf = new ( config )
type config struct {
SetZeroConfigByErrImagePull * SetZeroConfigByErrImagePull `mapstructure:"errImagePull" json:"errImagePull"`
SetZeroConfigByTooManyRestart * SetZeroConfigByTooManyRestart `mapstructure:"tooManyRestart" json:"tooManyRestart"`
AutoDelteEvictedPod * AutoDelteEvictedPod `mapstructure:"delteEvictedPod" json:"delteEvictedPod"`
AutoDelteTerminatingPod * AutoDelteTerminatingPod `mapstructure:"delteTerminatingPod" json:"delteTerminatingPod"`
}
// 设置读取配置信息
func InitConfig () {
workDir , err := os . Getwd ()
if err != nil {
panic ( fmt . Errorf ( "读取应用目录失败:%s " , err ))
}
viper . SetConfigName ( "config" )
viper . SetConfigType ( "yml" )
viper . AddConfigPath ( workDir + "/" )
// 读取配置信息
err = viper . ReadInConfig ()
if err != nil {
panic ( fmt . Errorf ( "读取配置文件失败:%s " , err ))
}
// 将读取的配置信息保存至全局变量Conf
if err := viper . Unmarshal ( Conf ); err != nil {
panic ( fmt . Errorf ( "初始化配置文件失败:%s " , err ))
}
}
type SetZeroConfigByErrImagePull struct {
Namespaces [] string `mapstructure:"namespaces" json:"namespaces"`
Hours string `mapstructure:"hours" json:"hours"`
Status [] string `mapstructure:"status" json:"status"`
Enable bool `mapstructure:"enable" json:"enable"`
}
type SetZeroConfigByTooManyRestart struct {
Namespaces [] string `mapstructure:"namespaces" json:"namespaces"`
Hours string `mapstructure:"hours" json:"hours"`
Status [] string `mapstructure:"status" json:"status"`
Counts int `mapstructure:"counts" json:"counts"`
MsgTitle string `mapstructure:"msgtitle" json:"msgtitle"`
ApiUrl string `mapstructure:"apiurl" json:"apiurl"`
Duration string `mapstructure:"duration" json:"duration"`
Enable bool `mapstructure:"enable" json:"enable"`
}
type AutoDelteEvictedPod struct {
Namespaces [] string `mapstructure:"namespaces" json:"namespaces"`
Enable bool `mapstructure:"enable" json:"enable"`
}
type AutoDelteTerminatingPod struct {
Namespaces [] string `mapstructure:"namespaces" json:"namespaces"`
Hours string `mapstructure:"hours" json:"hours"`
Enable bool `mapstructure:"enable" json:"enable"`
}
根据上面的代码, 可以得知 yaml 格式的配置文件具体要怎么配置了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
errImagePull :
namespaces : default
# 单位支持 ns、us(或µs)、ms、s、m、h
hours : 5s
status : ErrImagePull,ImagePullBackOff
enable : true
tooManyRestart :
namespaces : default
hours : 1s
status : CrashLoopBackOff,Error,Completed,RunContainerError
counts : 2
# 秒分时日月周
duration : "*/3 * * * * *"
# 告警信息title
msgtitle : "pod重启次数过多"
apiurl : "https://open.feishu.cn/open-apis/bot/v2/hook/xxxx"
enable : false
delteEvictedPod :
namespaces : default
enable : true
delteTerminatingPod :
namespaces : default
hours : 2m
enable : true
入口层
入口层这里做各种初始化工作,具体看注释,不做赘述。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
func main () {
// 初始化配置文件
cf . InitConfig ()
clientset , err := clientset . InitClient ()
if err != nil {
klog . Fatal ( err )
}
// 创建 Pod ListWatcher, v1.NamespaceDefault
podListWatcher := cache . NewListWatchFromClient ( clientset . CoreV1 (). RESTClient (), "pods" , "" , fields . Everything ())
// 创建队列
queue := workqueue . NewRateLimitingQueue ( workqueue . DefaultControllerRateLimiter ())
// 在 informer 的帮助下,将工作队列绑定到缓存
// 这样,我们确保无论何时更新缓存,都将 pod key 添加到工作队列中
// 注意,当我们最终从工作队列中处理元素时,我们可能会看到 Pod 的版本比响应触发更新的版本新
indexers := cache . Indexers { cache . NamespaceIndex : cache . MetaNamespaceIndexFunc }
informer := cache . NewSharedIndexInformer ( podListWatcher , & v1 . Pod {}, time . Minute * 5 , indexers )
informer . AddEventHandler ( cache . ResourceEventHandlerFuncs {
AddFunc : func ( obj interface {}) {
key , err := cache . MetaNamespaceKeyFunc ( obj )
if err == nil {
queue . Add ( key )
}
},
UpdateFunc : func ( old interface {}, new interface {}) {
newRes := new .( * v1 . Pod )
oldRes := old .( * v1 . Pod )
if newRes . ResourceVersion == oldRes . ResourceVersion {
// Two different versions of the same Resource will always have different RVs.
return
} else {
key , err := cache . MetaNamespaceKeyFunc ( new )
if err == nil {
queue . Add ( key )
}
}
},
DeleteFunc : func ( obj interface {}) {
key , err := cache . DeletionHandlingMetaNamespaceKeyFunc ( obj )
if err == nil {
queue . Add ( key )
}
},
})
// start controller
stopCh := make ( chan struct {})
defer close ( stopCh )
go informer . Run ( stopCh )
// start cronjob
stopCronCh := make ( chan struct {})
defer close ( stopCronCh )
// 等待所有相关的缓存同步,然后再开始处理队列中的项目
if ! cache . WaitForCacheSync ( stopCh , informer . HasSynced ) {
runtime . HandleError ( fmt . Errorf ( "timed out waiting for caches to sync" ))
return
}
controller := controller . NewController ( queue , informer )
go controller . Run ( 1 , stopCh )
go controller . Report ( stopCronCh )
sigs := make ( chan os . Signal , 1 )
signal . Notify ( sigs , syscall . SIGINT , syscall . SIGTERM )
go func () {
// pprof 性能分析,单纯只是拿来玩玩看的,不要也可以
// 启动一个 http server,注意 pprof 相关的 handler 已经自动注册过了
if err := http . ListenAndServe ( ":6060" , nil ); err != nil {
klog . Fatal ( err )
}
}()
<- sigs
// stopCh <- struct{}{}
stopCronCh <- struct {}{}
klog . Info ( "Stopping Pod controller" )
}
值得一提的是,我们这边也做了一个性能分析的接口 http.ListenAndServe(":6060", nil) ,通过访问 pod ip + 端口 可以查看 golang 服务的各项行指标。如果是正式上生产,为了安全考虑,可以在配置文件里面加多一个字段,来控制生产环境不开放这个接口。
结束语
通过 client-go 的 informer 机制来实现上述这些功能,可以做到实时清理 kubernetes 集群内各类状态异常的 pod ,且减少人力干预,节省人力成本。
起初也是没想到要做这个项目的,只不过最近刚好看了一些 kubernetes 源码相关方面的书籍后,想找点东西练手,后经查阅各方资料后,确认难度不算高之后才动手实践。
目前只是初级阶段,后续有机会我们可以再继续往更高一层发展,可以通过编写 Operater 的方法来重构这个项目,一起让我们拭目以待吧,让我们每天都进步一点点。