kubernetes排错-pod oom 内存持续增长
pod 运行一段时间后,内存持续增长,甚至 oom 的情况.
动机
容器化过程中,我们经常会发现 kubernetes 集群内 pod 的内存使用率会不停持续增长,加多少内存吃多少内存,如果对 cgroup 内存的构成不是很清楚的情况下,单纯看监控看不出什么问题。
经过一番查阅,目前总结出大致有 2 种导致这种情况的场景。
-
内存泄露
-
io 缓存
案例分析
我们先从内存泄露分析,刚好手头有个 pod 也是这种情况。
内存泄露
进入对应的 pod 内部。我们先看看它用了多少内存,prometheus 也是取这个值做为容器的内存使用率的。
|
|
我们查看 grafana ,内存使用率的采集结果与 cgroup 里面的记录一致。
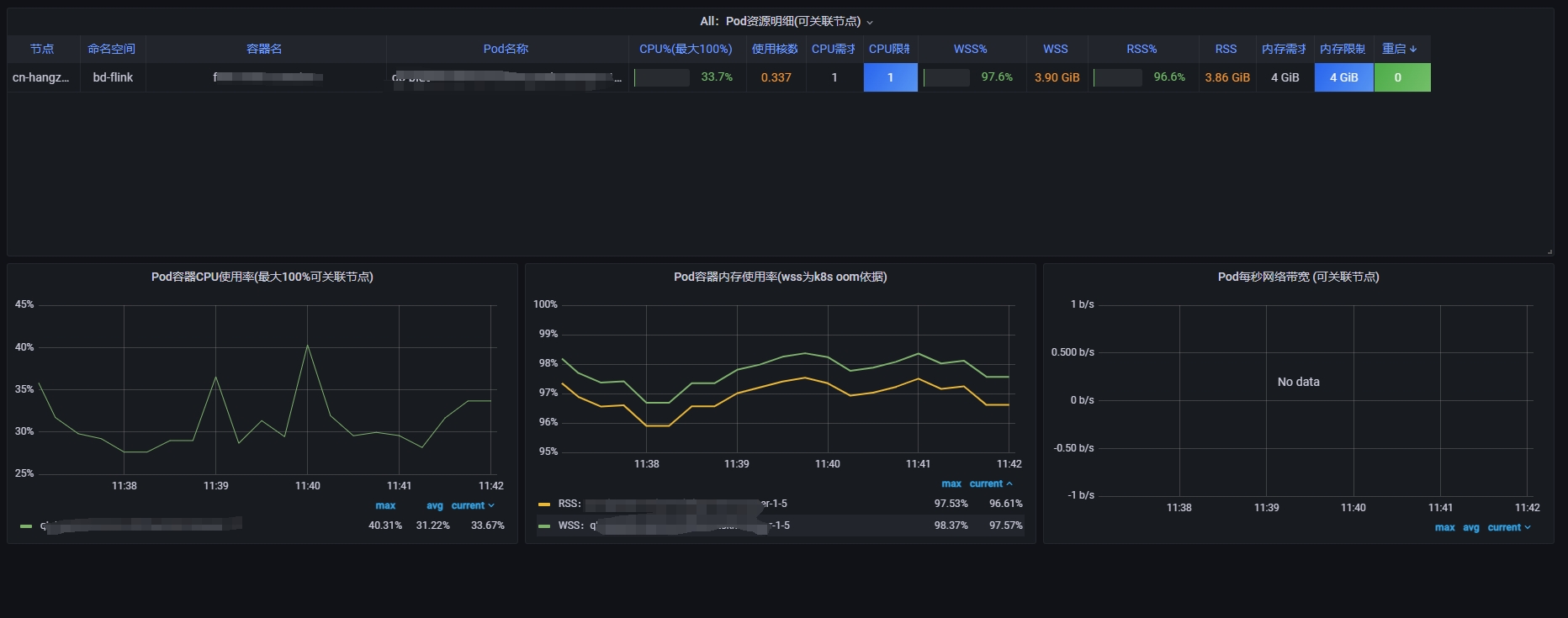
我们拉长一下记录看看。

很明显就是发生内存泄露了 ,接下来,我们看看 pod 容器内内存记录。
|
|
上面获取内存记录,我们主要关心:
total_cache、total_rss、total_inactive_anon、total_active_anon、total_inactive_file、total_active_file
分别代表的意思:
-
total_cache:表示当前pod缓存内存量
-
total_rss:表示当前应用进程实际使用内存量
-
total_inactive_anon:表示匿名不活跃内存使用量
-
total_active_anon:表示匿名活跃内存使用量,jvm堆内存使用量会被计算在此处
-
total_inactive_file:表示不活跃文件内存使用量
-
total_active_file:表示活跃文件内存使用量
rss 确实是使用了 3.9GB 的量,确实是 pod 容器的真实使用,那么基本就验证了要么程序确实内存不够,要么就是内存泄露了。
io 缓存
除了上面那种内存泄露的场景外,还有一种是 io 缓存导致的内存虚高。如下,wss 比 rss 高出不少,这还不算极端的,只是拿出这个举个例子。
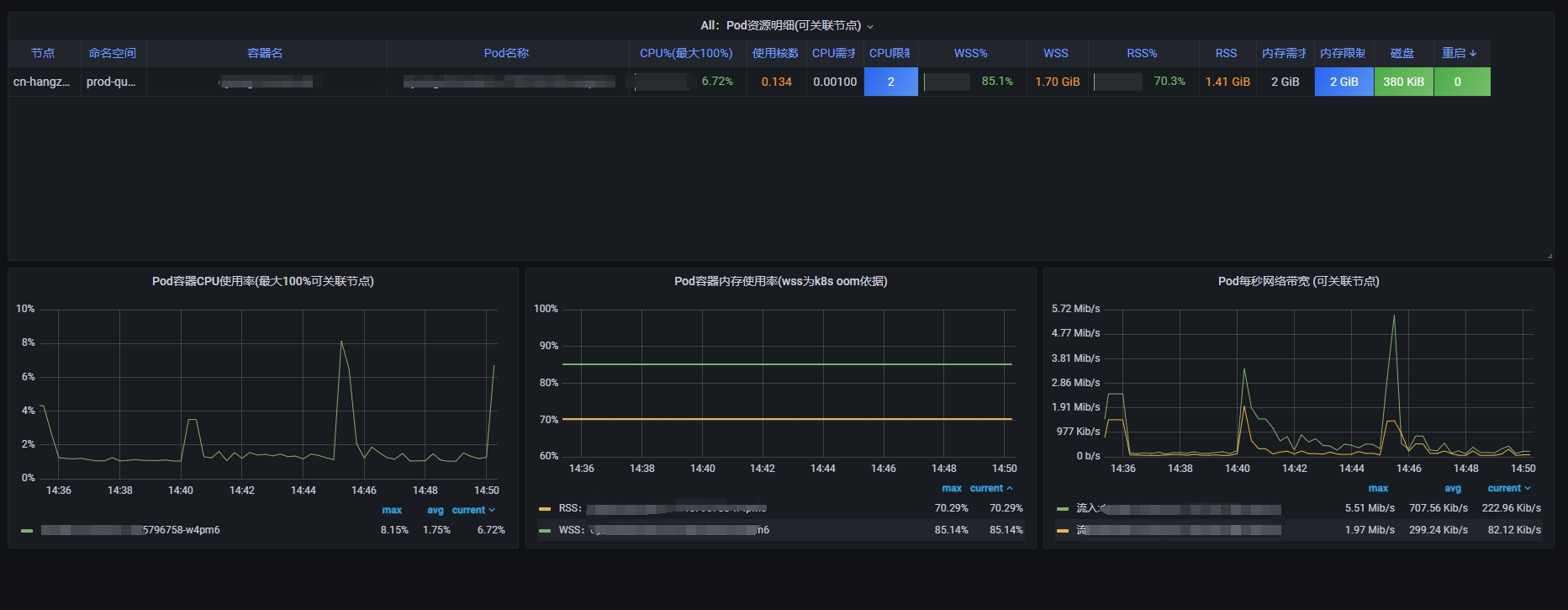
然后,我们来看下容器内存指标的组成结构。
-
container_memory_working_set_bytes
-
container_memory_rss
容器当前使用内存量: container_memory_usage_bytes = total_cache + total_rss
容器当前使用缓存内存: total_cache = total_inactive_file + total_active_file
container_memory_working_set_bytes:container_memory_working_set_bytes = container_memory_usage_bytes - total_inactive_file
带入上面两个公式,容器的工作集的等式可以拆解为:
|
|
-
total_rss为应用真实使用内存量,正常情况下该指标数值稳定,那为何该指标会持续上升而且一直维持很高呢?其实问题就出现在total_active_file上。 -
Linux 系统为了提高文件读取速率,会划分出来一部分缓存内存,即 cache 内存,这部分内存有个特点,当应用需要进行 io 操作时,会向 Linux 申请一部分内存,这部分内存归属于操作系统,当应用io操作完毕后,操作系统不会立即回收,当操作系统认为系统剩余内存不足时,才会主动回收这部分内存。
-
container_memory_working_set_bytes指标升高一部分是应用本身内存使用量增加,另一部分就是进行了 io 操作,total_active_file升高,该指标异常一般都是应用进行了io相关操作。
总结
知道这些情况后,然后就是解决方法:
-
如果是频繁写日志到磁盘或输出日志到标准输出的场景,可以紧张日志输出到标准输出,日志落盘做轮转,比如 50-100MB 一个文件做切割,保留最近几个日志文件即可。昨晚这些后,
container_memory_working_set_bytes的使用率会肉眼可见的回落。 -
如果是内存计算比较频繁的服务,可以现在程序的可用内存,比如 jvm ,10G 的 pod 内存,限制程序使用 8.5GB 的的内存,现在对外内存最大使用值 1.5GB,这样就可以预留足够的内存防止 pod oom 了。只是打个比方,具体还得根据真实场景所需设置。
-
wss的值:
container_memory_working_set_bytes = total_active_file + total_rss