apiVersion:keda.sh/v1alpha1kind:ScaledObjectmetadata:name:{scaled-object-name}spec:scaleTargetRef:apiVersion:{api-version-of-target-resource} # Optional. Default:apps/v1kind:{kind-of-target-resource} # Optional. Default:Deploymentname:{name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObjectenvSourceContainerName:{container-name} # Optional. Default:.spec.template.spec.containers[0]pollingInterval: 30 # Optional. Default:30secondscooldownPeriod: 300 # Optional. Default:300secondsidleReplicaCount: 0 # Optional. Default:ignored, must be less than minReplicaCount minReplicaCount: 1 # Optional. Default:0maxReplicaCount: 100 # Optional. Default:100fallback:# Optional. Section to specify fallback optionsfailureThreshold:3# Mandatory if fallback section is includedreplicas:6# Mandatory if fallback section is includedadvanced:# Optional. Section to specify advanced optionsrestoreToOriginalReplicaCount: true/false # Optional. Default:falsehorizontalPodAutoscalerConfig:# Optional. Section to specify HPA related optionsname:{name-of-hpa-resource} # Optional. Default:keda-hpa-{scaled-object-name}behavior:# Optional. Use to modify HPA's scaling behaviorscaleDown:stabilizationWindowSeconds:300policies:- type:Percentvalue:100periodSeconds:15triggers:# {list of triggers to activate scaling of the target resource}
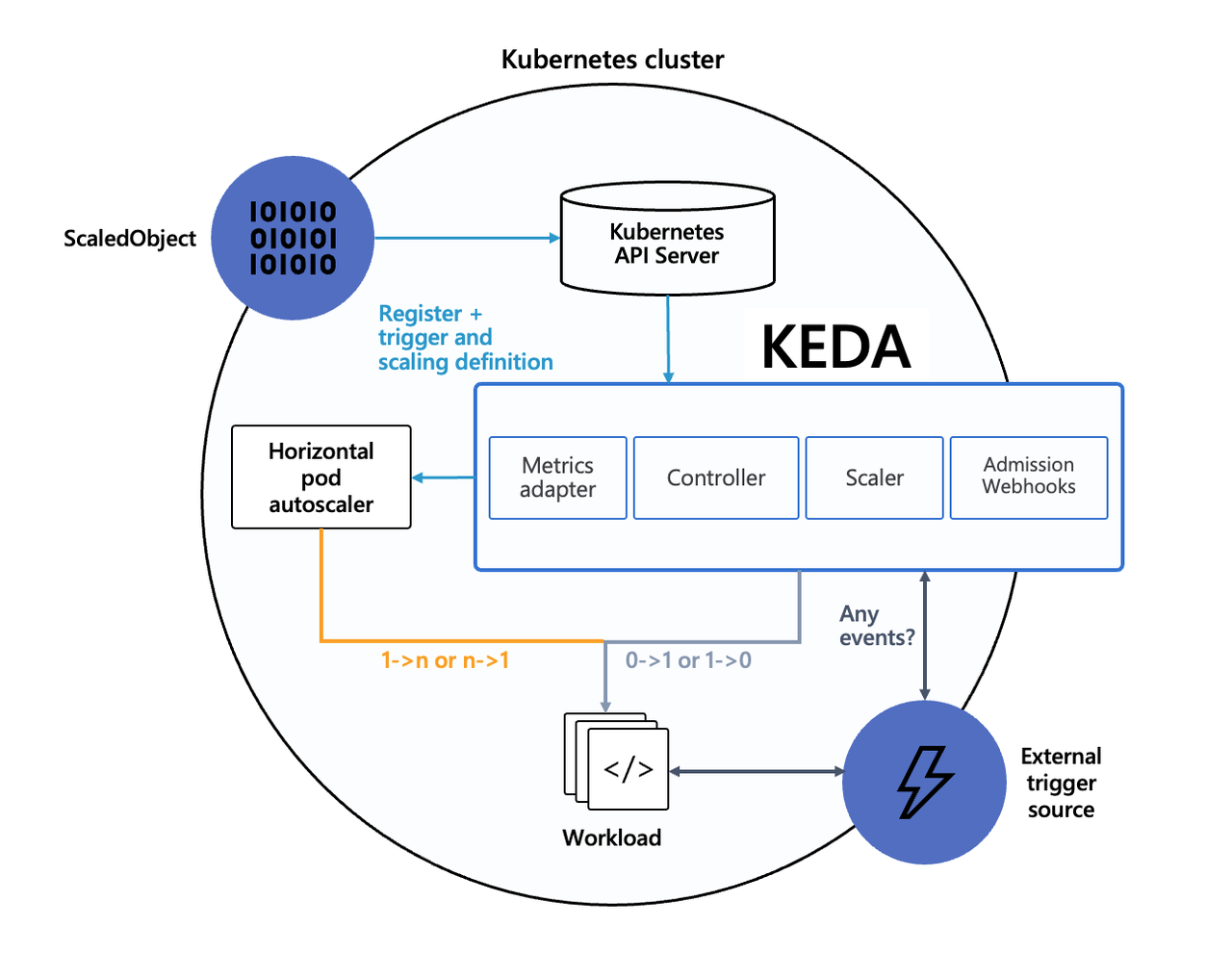
ScaledObject 大致分两部分:
scaleTargetRef
目标资源对象的详细的详细配置参数。
triggers
使用何种事件源,以及事件源的详细配置参数。
前面我们提到过 KEDA 内置了几十种内置的缩放器,我们会拿其中几个比较有代表性的使用场景出来演示一下 demo 。
我们创建一份 ScaledObject ,triggers 使用 cpu 资源类型来做事件源,cpu 使用率超过 50% 以后,HPA 会使用公式计算是否开始扩缩容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion:keda.sh/v1alpha1kind:ScaledObjectmetadata:name:hpa-demo-cpunamespace:defaultspec:scaleTargetRef:name:hpa-demominReplicaCount:1maxReplicaCount:10triggers:- type:cpumetricType:Utilization# Allowed types are 'Utilization' or 'AverageValue'metadata:value:"50"
我们看到 ScaledObject 已经被创建。
它的原理也是通过创建原生 HPA 来实现的。
启动无限发送请求,观察扩缩容的情况,效果跟原生是一样的。
2.prometheus
很多时候,使用 cpu 和 memory 资源类型并不能很好地反应服务的真实负载情况,比如 web 服务,qps 达到一定量的时候,有可能 cpu 和 内存使用率都很低,但是后端 Pod 的连接数已经满了这种情况。
apiVersion:keda.sh/v1alpha1kind:ScaledObjectmetadata:name:hpa-demo-promnamespace:defaultspec:scaleTargetRef:name:hpa-demominReplicaCount:1maxReplicaCount:10triggers:- type:prometheusmetadata:serverAddress:http://rancher-monitoring-prometheus.cattle-monitoring-system.svc:9090metricName: nginx_ingress_controller_requests # DEPRECATED:This parameter is deprecated as of KEDA v2.10 and will be removed in version 2.12threshold:'100'query:sum(rate(nginx_ingress_controller_requests{ingress="hpa-demo-ingress"}[2m]))
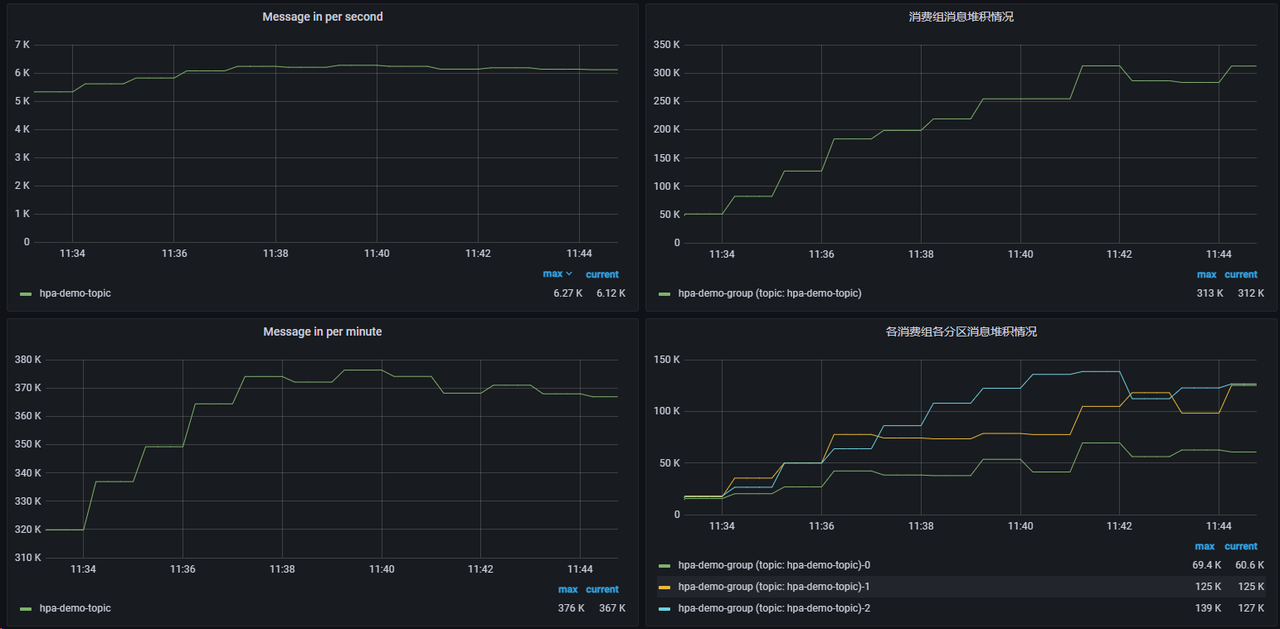
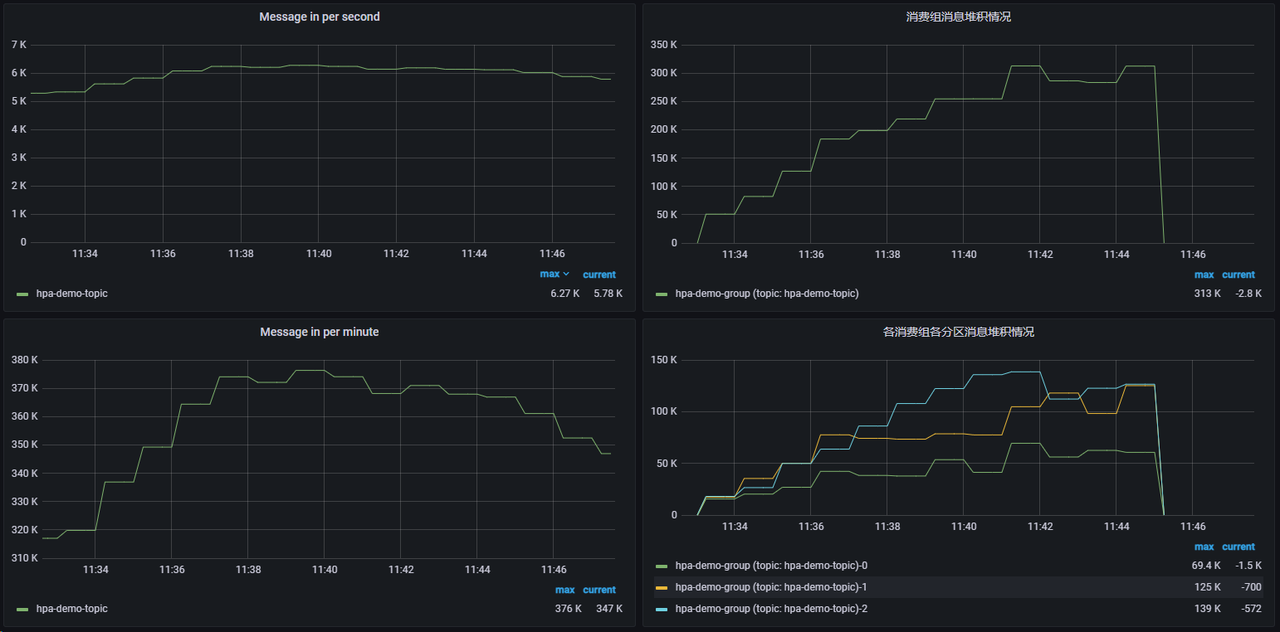
apiVersion:keda.sh/v1alpha1kind:ScaledObjectmetadata:name:hpa-demo-kafkanamespace:defaultspec:scaleTargetRef:name:hpa-demo-consumerpollingInterval:30minReplicaCount:1# Pod 数量不能大于分区数maxReplicaCount:3triggers:- type:kafkametadata:bootstrapServers:192.168.21.3:9093consumerGroup:hpa-demo-grouptopic:hpa-demo-topic# OptionallagThreshold:"5000"offsetResetPolicy:latest
注意
maxReplicaCount 不能大于 topic 的分区数,虽然大于这个数扩缩功能也没什么问题,但是多出来的 Pod 不会起到消费的作用,只会白白浪费资源而已。