Chain INPUT (policy ACCEPT)target prot opt source destination
KUBE-NODE-PORT all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes health check rules */
ACCEPT udp -- 0.0.0.0/0 169.254.20.10 udp dpt:53
ACCEPT tcp -- 0.0.0.0/0 169.254.20.10 tcp dpt:53
KUBE-FIREWALL all -- 0.0.0.0/0 0.0.0.0/0
Chain KUBE-FIREWALL (2 references)target prot opt source destination
DROP all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes firewall for dropping marked packets */ mark match 0x8000/0x8000
DROP all -- !127.0.0.0/8 127.0.0.0/8 /* block incoming localnet connections */ ! ctstate RELATED,ESTABLISHED,DNAT
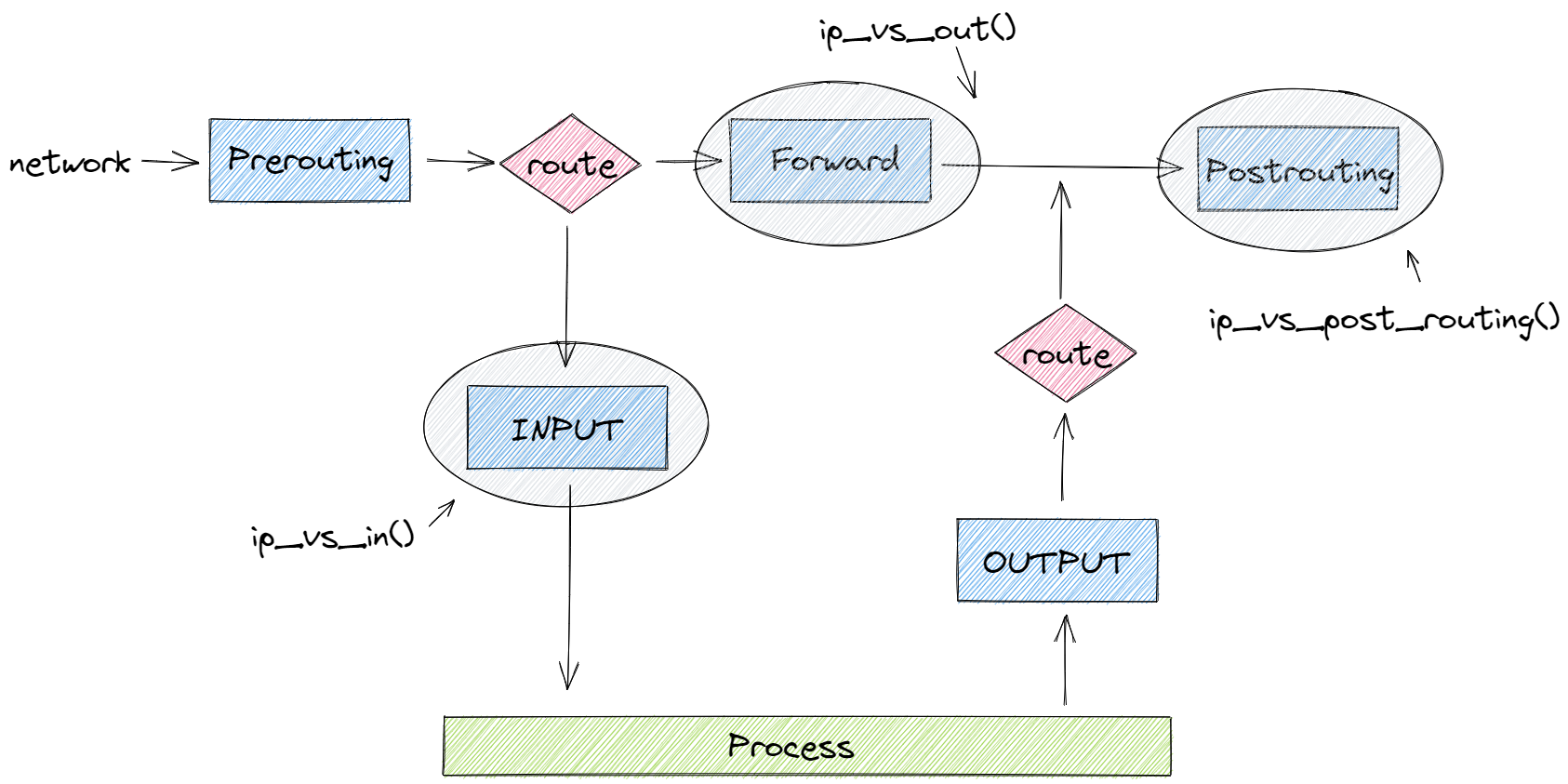
然后执行 ipvs 的 hook ,进行 DNAT 。
将 目标ip 从 service 的 ClusterIP 替换为 service 后端的某个真实的 pod ip ,端口从 service 的 目标端口 替换为 service 后端的某个真实的 pod 端口,源ip 和 源端口 不变,完成 DNAT 后,然后将数据直接送入 POSTROUTING Chain 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Chain POSTROUTING (policy ACCEPT)target prot opt source destination
KUBE-POSTROUTING all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes postrouting rules */
MASQUERADE all -- 169.254.123.0/24 0.0.0.0/0
RETURN all -- 10.80.0.0/16 10.80.0.0/16
MASQUERADE all -- 10.80.0.0/16 !224.0.0.0/4
RETURN all -- !10.80.0.0/16 10.80.1.128/25
MASQUERADE all -- !10.80.0.0/16 10.80.0.0/16
Chain KUBE-POSTROUTING (1 references)target prot opt source destination
MASQUERADE all -- 0.0.0.0/0 0.0.0.0/0 /* Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose */ match-set KUBE-LOOP-BACK dst,dst,src
RETURN all -- 0.0.0.0/0 0.0.0.0/0 mark match ! 0x4000/0x4000
MARK all -- 0.0.0.0/0 0.0.0.0/0 MARK xor 0x4000
MASQUERADE all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */
数据在 POSTROUTING chain 中完成 MASQUERADE SNAT 。
这时 源ip 为下一跳路由所使用网路设备的 ip ,源端口为随机端口,目标ip 为映射选择的 pod ip ,目标port 为映射选择的 port ,并做了 conntrack 记录,便于回包的时候,把 源ip 从 目标pod ip 改回 DNAT 之前的 service 的 ClusterIP 。
func(proxier*Proxier)syncProxyRules(){...// ipvs call
serv:=&utilipvs.VirtualServer{Address:net.ParseIP(ingress),Port:uint16(svcInfo.Port()),Protocol:string(svcInfo.Protocol()),Scheduler:proxier.ipvsScheduler,}ifsvcInfo.SessionAffinityType()==v1.ServiceAffinityClientIP{serv.Flags|=utilipvs.FlagPersistentserv.Timeout=uint32(svcInfo.StickyMaxAgeSeconds())}iferr:=proxier.syncService(svcNameString,serv,true,bindedAddresses);err==nil{activeIPVSServices[serv.String()]=trueactiveBindAddrs[serv.Address.String()]=trueiferr:=proxier.syncEndpoint(svcName,svcInfo.NodeLocalExternal(),serv);err!=nil{klog.ErrorS(err,"Failed to sync endpoint for service","service",serv)}}else{klog.ErrorS(err,"Failed to sync service","service",serv)}...}func(proxier*Proxier)syncEndpoint(svcPortNameproxy.ServicePortName,onlyNodeLocalEndpointsbool,vs*utilipvs.VirtualServer)error{...for_,epInfo:=rangeendpoints{ifepInfo.IsReady(){readyEndpoints.Insert(epInfo.String())}ifonlyNodeLocalEndpoints&&epInfo.GetIsLocal(){ifepInfo.IsReady(){localReadyEndpoints.Insert(epInfo.String())}elseifepInfo.IsServing()&&epInfo.IsTerminating(){localReadyTerminatingEndpoints.Insert(epInfo.String())}}}...// 如果 onlyNodeLocalEndpoints 为true, newEndpoints = localReadyEndpoints
newEndpoints:=readyEndpointsifonlyNodeLocalEndpoints{newEndpoints=localReadyEndpointsifutilfeature.DefaultFeatureGate.Enabled(features.ProxyTerminatingEndpoints){iflen(newEndpoints)==0&&localReadyTerminatingEndpoints.Len()>0{newEndpoints=localReadyTerminatingEndpoints}}}...newDest:=&utilipvs.RealServer{Address:net.ParseIP(ip),Port:uint16(portNum),Weight:1,}ifcurEndpoints.Has(ep){// check if newEndpoint is in gracefulDelete list, if true, delete this ep immediately
uniqueRS:=GetUniqueRSName(vs,newDest)if!proxier.gracefuldeleteManager.InTerminationList(uniqueRS){continue}klog.V(5).InfoS("new ep is in graceful delete list","uniqueRS",uniqueRS)err:=proxier.gracefuldeleteManager.MoveRSOutofGracefulDeleteList(uniqueRS)iferr!=nil{klog.ErrorS(err,"Failed to delete endpoint in gracefulDeleteQueue","endpoint",ep)continue}}// 添加 ipvs 规则
err=proxier.ipvs.AddRealServer(appliedVirtualServer,newDest)iferr!=nil{klog.ErrorS(err,"Failed to add destination","newDest",newDest)continue}...}
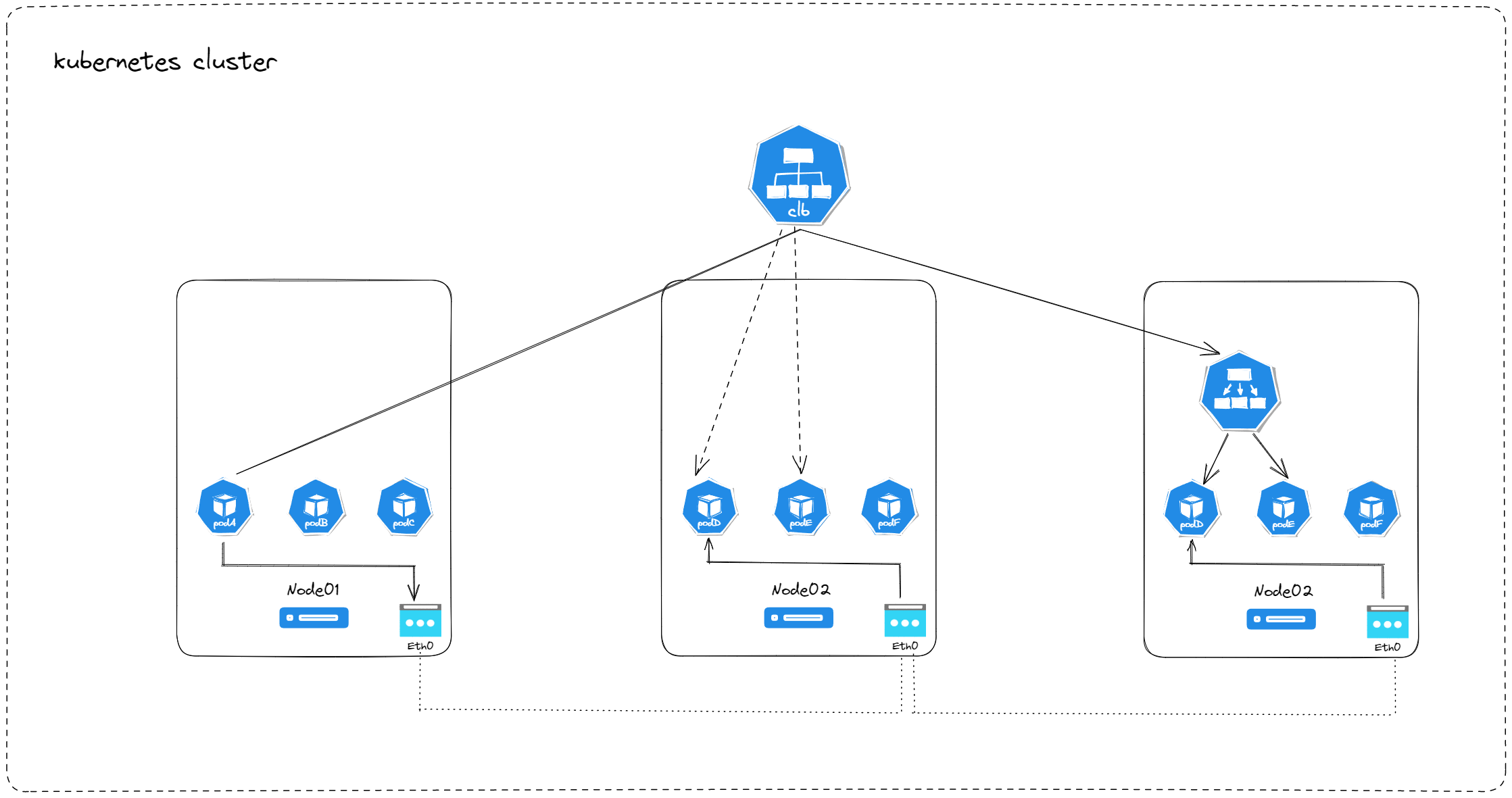
我们测试一下,出于安全考虑,我这边不使用真实的 ip ,假设,lb 的 ip 是 111.111.111.111 ,如果要自己验证的,你们根据自己的实际情况替换。
我们先部署一个 busybox 容器,用来测试流量能否通过 lb 访问到内部访问。
找一台没有运行 nginx pod 的节点,在节点上,执行 ipvsadm -Ln|grep -A 2 111.111.111.111 。